Remember that correlation is a linear relationship between two variables. If I find the variables in my hypothesis have little relationship to one another, then I want to think about p value, which is about likelihood of repeatable one set of outcomes to occur in other experiments.
Plain english means I found a loose relationship that someone is not likely to find if the tried to validate my outcomes. When somebody tries to repeat my outcomes, that’s called peer review and it adds a another level of rigor to prove your work was correct to begin with, not unlike proofs and geometry.
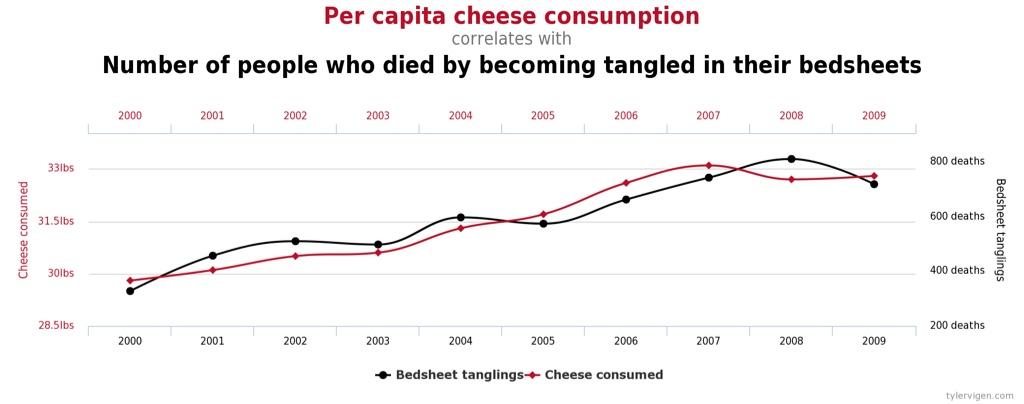
In the case of high (more correctly, strong) correlation and a high likelihood of repeatability, you can end up with spurious correlation such as this example where we find cheese that’s consumed by people, the more likely it is death by bedsheet will occur.
Source:
https://www.tylervigen.com/spurious-correlations
In other instances where weak correlation is calculated with a p value indicating high repeatability you run the chance of overlooking the possibility of a research gap being just as likely as other factors that could contribute to that outcome.
That’s kind, but I’m just an amateur at this stuff despite a long ago education in empirical research and methods.
In my day job I look at business problems to determine if we can teach/train employees behaviors that contribute to improved business performance. My client’s generally want training so they can create a paper trail showing they’ve done everything possible. Then I show up and ask for all their data around the business problem to gain a better understanding. I have to defend my recommendations and things like correlation do contribute to real root cause analysis. Many times my recommendations are counter to the client’s demands so I have to dazzle them with empirical data.
Robinson & Robinson’s
Performance Consulting is a good read to understand what I do.